Computing: Please, Mind Your Language!

A family of algorithmic pen plotted drawings, each presented with the binary text for a Universal Turing Machine (UTM), were created for an exhibition in Manchester on the occasion of the Ninth International Symposium on Electronic Art (1998). (Source)
A Computational Universe
The brilliant German civil engineer Konrad Zuse made a great practical achievement; his functional program-controlled Turing-complete Z3 became operational in May 1941. But his most brilliant conceptual achievement was in 1967 when Zuse suggested that the universe itself is running on a cellular automaton or similar computational structure; what we know now as digital physics. In 1969, he published the book “Calculating Space” challenging the long-held view that some physical laws are continuous by nature1. This idea has attracted a lot of attention, since there is no physical evidence against Zuse’s thesis, but practically isolated Zuse from the scientific community for a very long time. Later on, in their attempt to unify relativity with quantum mechanics, many physicists are realizing that information is more fundamental than space and time; that space-time might be emergent from information exchange and processing in our discrete computational universe.
Information processing and computations are found everywhere in the natural world; inspiring us with many new computational paradigms every day. Information processing is found on the level of quantum mechanics and how elementary particles behave, in the miraculous way of manufacturing protein from DNA, in the way swarms of insects optimize their search for food, and much more.
Information means distinctions between things. When we create abstractions we choose to ignore information about many distinct concrete objects in order to conceptually unify them into one abstraction. The level of abstraction depends on what information we decide to ignore and what we decide to keep. In physics, we need to investigate constraints and initial conditions, in the form of measurements, on the studied physical system by performing experiments as part of the information framework we deal with to arrive at accurate models. In computer science, we do not require any specific constraints or initial conditions in general; unless we are creating accurate physical simulations. We are much more free to investigate any computational universe we can imagine possible, as long as it can be computed in reasonable time-space constraints. The key concepts here are computational ideas and programming languages.
Language, Thought, and Imagination

Computing is done by programming computers, programming requires programming languages, and programming languages come in many forms and flavors. The creative process of software development, in general, is certainly related to language, thought, and imagination. For geometric modeling and geometric processing applications, the correct selection of a programming language is absolutely fundamental.
In the realm of philosophy of language, the “ideational theory of meaning“, originally developed by John Locke in the 17th century, has 3 fundamental theses:
- That the primary end of language is the communication of thought.
- That thinking at its most basic consists in ‘having ideas’; that is, thinking is fundamentally imaginative in nature.
- That words acquire their power to express thoughts by being made, through custom and convention, to represent or signify “ideas” in the minds of those who use them.
On some or many occasions we may “think in words”, but there is a fundamental level of thought at which it is not linguistic but imaginative in nature: a level at which we “think in ideas”. Speaking loosely, it might almost be said that imagination is a kind of surrogate perception; that to exercise one’s imagination is to rehearse or anticipate actually or possible episodes of perceptual experience, though with a degree of voluntary control that is characteristically absent from perception itself; in perception one can direct one’s attention at will, but has very little voluntary control over what is perceived once one’s attention has been fixed. Imagination, like perception, may be classified by reference to its sensory modes and thus we have visual, auditory and tactile imagination, just as we have these forms of perception. Unsurprisingly, there is neuropsychological and neurophysiological evidence that many of the same areas of the cortex are typically engaged in imagination as in perception. These observations may suffice to highlight the intimacy of the relation between the two2.
The way language can affect our thought process is not simple; there is always a two-way mutual influence between language and idea. Some say that our language doesn’t force us to see only what it gives us words for, but it can affect how we put things into groups3. We learn to group things that are similar and give them the same label, but what counts as being similar enough to fall under a single label may vary from language to language. In other words, the influence of language isn’t so much on what we can think about, or even what we do think about, but rather on how we break up reality into categories and label them. And in this, our language and our thoughts are probably both greatly influenced by our culture. Others say the language we speak broadly affects or even determines the way we experience the world, from the way we perceive it, to the way to categorize it, to the way we cognize it. There are definite differences in perception between people speaking different languages. Studies have shown that changing how people talk changes how they think. Research has been uncovering how language shapes even the most fundamental dimensions of human experience: space, time, causality and relationships to others4.
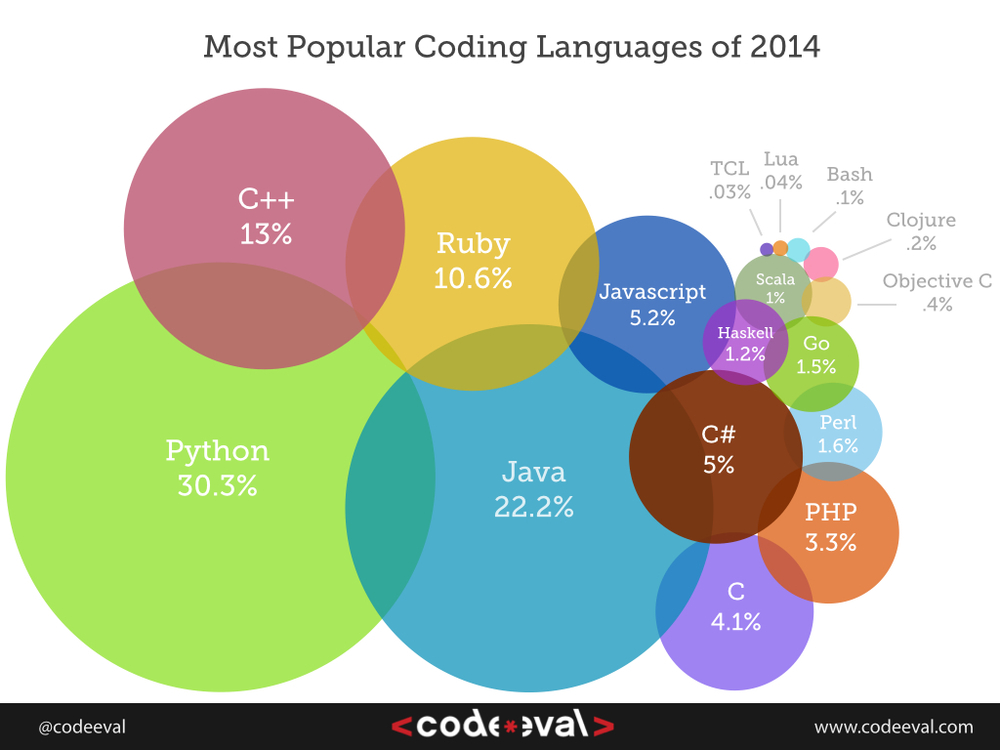
Computer languages are human in their expressive nature but computational in their intended function. This dual aspect of programming languages is, in my opinion, the main reason behind the rise and fall of many programming languages and code-development paradigms. No one today uses Assembly for developing complex software systems; while having a huge (theoretical) computational power, the “human side” of Assembly (readability, writability, maintainability, testability, etc.) is almost non-existent. Applying the ideational theory of meaning to computing, our ultimate goal is to create a computer that can directly understand our internal thoughts and ideas about what we need to compute; which is currently just a great plot for a science fiction story and no more. The next best thing is to create computational languages that we can express our ideas in the least effort and largest correspondence possible. Our general purpose programming languages, especially the object-oriented ones, go a long way to that goal, but we certainly can, and need, to do much more to get closer to “computing with ideas” rather than turning ourselves into imagination-free bio-computers.
Our Many Tongues

As a software developer, I realized early in my programming life that not all languages are created equal. It’s not just that different languages have different features, but the existence of profoundly distinct ways of thinking; we call them Programming Paradigms. Often to create a complex software system we need to use more than one paradigm for different parts of the system. As stated in an IEEE Software issue on multiparadigm programming5:
But today’s applications are seldom homogeneous. They are frequently complex systems, made up of many subcomponents that require a mixture of technologies. Thus, using just one language technology and paradigm is becoming much less common, replaced by multiparadigm programming in which the heterogeneous application consists of several subcomponents, each implemented with an appropriate paradigm and able to communicate with other subcomponents implemented with a different paradigm. When more than one language is used, we call this polyglot (“many tongues”) programming.
Internet and intranet applications are inherently heterogeneous, often combining languages like JavaScript, Flash, and HTML in the user interface (UI), Java, C#, and Ruby in the middle tier, and SQL in the database. Not only are many languages involved, but there are also many paradigms, with SQL implementing the relational model, and object-oriented programming (OOP) dominating the middle and UI tiers. Even some “single-tier” desktop and server applications mix implementation languages, such as a fast, compiled “kernel” language for performance-sensitive components and a scripting language for integrating those components to create features, make extensibility easier, and so on.
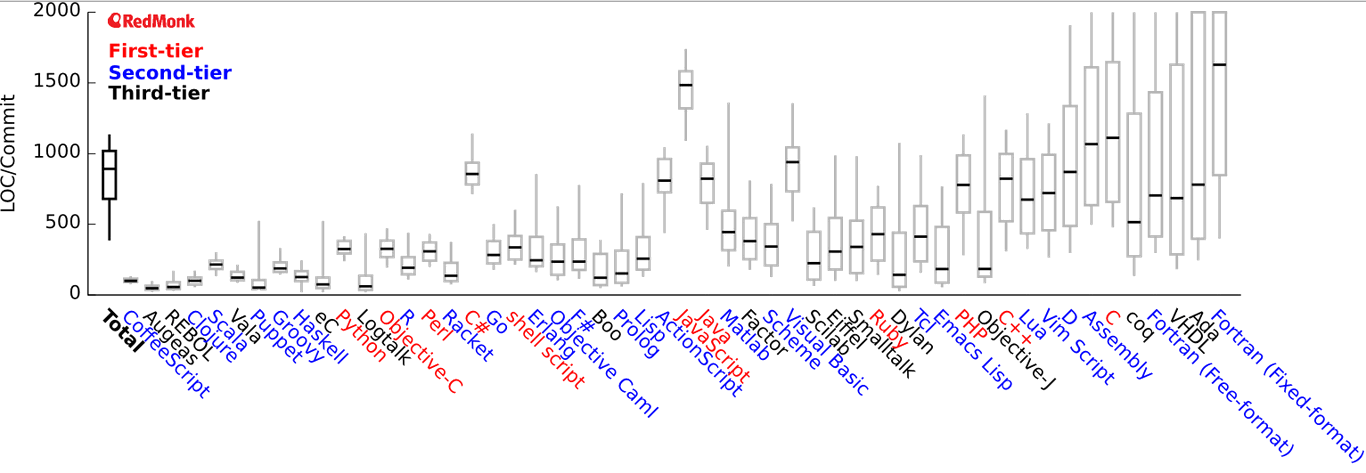
Personally, I’ve been using several paradigms in my software. I started out using procedural (imperative) programming with VB and C, then I discovered object-oriented programming with C++, VB.NET, and C#, followed by relational SQL programming, some logic programming with Prolog in the AI course I teach, and finally some functional programming in F#. Each paradigm required a basically different way of thinking and expressing (coding). The controversy between language philosophers about how language affects ideas is settled for me; with each programming paradigm, my way of thinking about computation is indeed changed considerably. Apart from the technical advantage of integrating several paradigms, for a software engineer, it’s necessary to think and code in several paradigms to reach a good understanding of the concept computation in general. You may have a preferred paradigm in which you can think clearly and fluently, but only by learning other programming paradigms you would appreciate the universal generality and relevance of information and computing to our life in every aspect. This multi-paradigm insight also inspires very good ideas about explorations to the Computational Universe, the physical and the non-physical. The presence of so much programming paradigms strongly indicates the many dimensions of computing. Each computational field in physics, biology, engineering, and science will have its own method of thinking and “space of computational imagination”; rightfully requiring its own domain-specific language for expressing such ideas. Now the ability to compute is not just for computer scientists and software engineers, it should be a right for every researcher\practitioner in all fields of science; this is not the current state of matters as one might think.
Getting Lost in a Public Library
General purpose programming languages (GPLs) are great tools, we think they can be used to create any possible computation; but can they really be so? Assembly can also be used for general purpose programming, but very few use it nowadays. GPLs provide general computational abstractions easing the creation of software; abstractions like subroutines, classes, objects, numerical variables, iteration, and conditional branching. These are similar to well organized “building standards” for adding water pipes and electrical wiring inside buildings. These abstractions are not intended, or even well understood for that matter, for end users; they are made by software people to be used by software people. The problem a scientist faces in order to exercise his “right to compute” is that he has to spend a considerable time learning a complex low-level language like C++ to guarantee the efficiency of his computations and integration with other “reusable” software libraries. Now practitioners and researchers that are not software engineers have a limited set of options to practice their right for digital computation6:
- Take the difficult road to learning a GPL, while studying their original fields, and create private libraries for their domain based on their own methods of thinking; facing software horrors like memory management, numerical error control, and bug tracking on their own.
- Come together and create super large libraries, with thousands or millions of lines of code, for their collective domain specific ideas. Then any newcomer to their field will have to learn not only the abstract concepts and practical techniques of their domain of knowledge but also the intricate behavior of the library in addition to the hosting GPL; things like general library and specific algorithm initialization, external I\O data types for data exchange, error reporting behavior, data reporting methods, and many more.
- Use the programming skills of software engineers, that are not aware of their specific abstractions and domain of knowledge, to develop software systems usable through graphical user interfaces that may never cover all aspects of the computational tasks at hand, also requiring considerable learning efforts, and perhaps provide some API for integration with other libraries.
Software libraries created with GPLs are inevitable, but their direct use by non-software specialists is not. Others have written excellent fast libraries that perform complex computational tasks for us. Like one interacts with the water pipes and electrical wiring at home through elegant simple to use interfaces, we must hide our libraries behind the simple to use interfaces; with abstractions relevant to our domains of abstractions not to general computing abstractions. Two approaches are used for such simpler programmable interfaces. The first is an architecture referred to as “components + scripts = applications”. It’s a “best of both worlds” solution, flexible and extensible, yet still providing high performance where necessary. The second is by using Domain Specific Languages (DSLs) that enable end-user programming in the most relevant and expressive way to his domain of ideas.
Joys of The Pythonistas

Compared to computer scientists and software engineers, many scientists and engineers practice programming for half or more of their work time, they are usually self-taught programmers with not enough background or training in computer science. They tend to use inefficient programming practices, and often select the wrong programming languages for the task at hand. They usually try doing everything using a single GPL (C++, Fortran, C#, Java, …) that they invest large amounts of time trying to study. Scientific programming needs rapid prototyping (to explore the largest number of ideas in the smallest time possible), efficiency for computational kernels, the use of pre-written libraries and packages (for vectors, matrices, modeling, simulation, visualization, etc.), and extensibility through, for example, web front-ends and database back-ends. One solution that found great acceptance among these hard working knowledge seekers is called Python. Python is very successful among scientists and engineers, among other disciplines. It’s a strongly but dynamically typed scripting GPL with strong object-oriented features. Python’s main strengths are being intuitive, readable, open source, free, with a large well supported, well documented scientific library. Its design is that of a small core language with a large standard library and an easily extensible interpreter.
Many computer folks would say Python is too slow compared to Fortran or C++; generally speaking, they are right. Native Python code may execute 10 times slower than C++ or Fortran. But at the same time, Python code is 10 times faster to write than C++ and Fortran; its compactness may give additional time savings during bug tracking and maintenance. For the world of scientific computation, many slow-downs are due to algorithmic complexity; a researcher friend once told me he made a modification to an algorithm that made it’s Matlab implementation several times faster than its C++ implementation. The remaining performance-critical code can always be factored out into fast libraries in Fortran or C++ and called directly from the main clear and easy to maintain “gluing code” created with Python. The overall economic saving is not a trivial thing; when Fortran was invented computer time was much more expensive than programmer time, in the 1990’s that situation reversed and now many consider ease of programming much important than the cost of hardware for many applications. Not realizing these facts is a serious problem with many computational systems. As William Allan Wulf said:
More computing sins are committed in the name of efficiency (without necessarily achieving it) than for any other single reason – including blind stupidity.
Python is good for rapid prototyping, plotting and visualization, numerical computing, web and database programming, and the creation of all-purpose glue code; it’s ideal for scientific computing investigations. Like Matlab, Python is interpreted with powerful I/O and plotting capabilities; Python is better as a more powerful GPL while being free, open source software, Matlab certainly costs much. Compared to C++, python has a superior scientific oriented standard library while being much easier to learn, write, and maintain; it can still inter-operate with existing C and C++ libraries easily. Like C# and Java, Python is a well-designed language while being much simpler to use. But the static typing capabilities of Java and C# make Python less attractive for many software developers; static typing catches many logical errors at design time. Some of the widely used libraries for Python include NumPy, SciPy, Matplotlib, Mayavi, SymPy (that includes a module for symbolic Geometric Algebra), VPython, and IPython. Python has been awarded a TIOBE Programming Language of the Year award twice (in 2007 and 2010), which is given to the language with the greatest growth in popularity over the course of a year, as measured by the TIOBE index. The design of Python has influenced many following programming languages.
Changing Computational Orientations
The scripting architecture of Python is great, but it suffers from the same basic abstraction problem as GPLs do. Each scientific and engineering field has its own set of common abstractions. For example, the same linear mathematical models can be used for many systems in electrical, mechanical, fluid, and construction engineering but each field defines its own language, including what ideas to group together and what ideas to ignore, for information exchange and computation. The computational base may be generally the same but the abstraction interface is quite distinct between those fields; this is where Domain Specific Languages shine. DSLs can be used to solve the computational form of the famous “last mile” problem in communications and transportation; where the things to be communicated or transported are computational ideas between domain-compatible recipients.
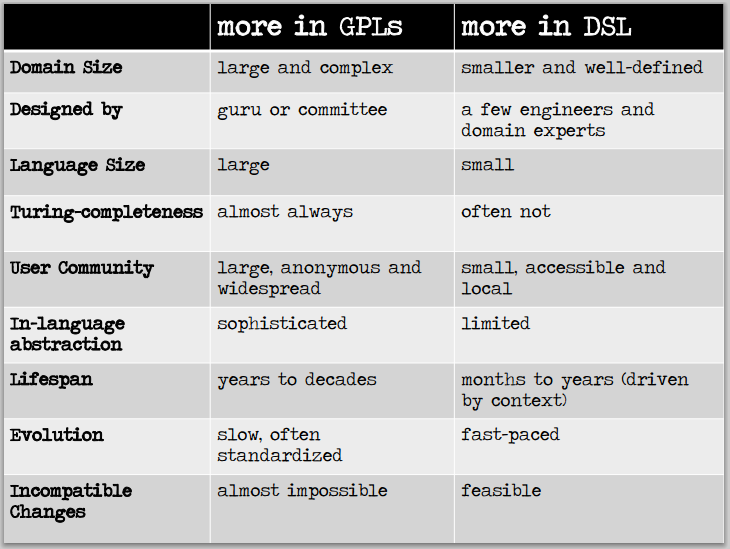
When trying to find discriminating definitions for GPLs and DSLs you may get surprised to find more “statements of impression” than solid consistent definitions. The distinction between DSLs and GPLs is not sharp but rather gradual7. Many GPLs started out as DSLs and then gained enough popularity to be called general purpose. When searching for features that make a language labeled domain specific, you find the general idea going around DSLs being ad hoc, custom made, non-general, having limited expressiveness, often leading to language cacophony, requiring much training, less technically supported, and having a small user base. The reason behind such impressions is the absence of the following points from the minds of many:
- All computer languages are initially ad hoc. No single language, GPL or DSL, can serve as a general solution for expressing all computational ideas. This fact is manifested in the many languages out there each having strengths and weaknesses depending on the way of intended use.
- Generality is a blurry feature of many computer languages. Any Turing-complete language can be, theoretically, used as a general-purpose programming language. The main reason that GPLs are called general is that many people from many diverse domains use them. The fact is that GPLs are actually based on computer science types of abstractions; they are domain specific where the domain is computer science or one of its sub-domains (a.k.a. programming paradigms). Computer science is, in effect, forcing its abstractions and languages on all other fields for historical reasons.
- As Martin Fowler states clearly, we already have a cacophony of frameworks that programmers have to learn. That’s the inevitable consequence of reusable software, which is the only way we can get a handle on all the things software has to do these days. In essence, a DSL is nothing more than a fancy facade over a framework. As a result, they contribute little complexity over what is already there. Indeed a good DSL should make things better by making these frameworks easier to use. The same logic applies to training where training on a DSL is much easier than training on its base library or framework.
- Many DSLs are generally much simpler than GPLs specifically because they serve a smaller number of very specialized people. A good architecture should be a well-supported library or framework with a large user base on which we develop several simple DSLs for several domains. The complexity should be mostly in the library while the interface should remain simple; just like the interfaces we use at home for devices and water supplies.
The actual difficulty facing DSLs is their design and implementation process; the term Language Oriented Programming was created for this purpose. Designing a good usable DSL is relatively complex, it’s not for the average programmer; it requires good experience not just with the domain of the DSL but in computer language design in general. A good DSL designer will conform to some set of general guidelines that are useful for such task. For a software engineer like me, I found great joys and gained valuable experience, similar to what Walter Bright’s expressed in his article here when designing my first DSL for geometric algebra modeling: GMacDSL. I was originally “object-oriented” but now I’m “language oriented”. Instead of thinking about complex problems as a set of interacting objects of some classes, I can now imagine the problem as a set of domain entities or components that can be organized using a language for performing the desired computation. Changing one’s “computational orientation” is not an easy process but it is definitely rewarding; instead of thinking in objects or procedures like a computer does, I now think in the language of geometric modeling computations like normal humans often do. As Sergey Demitriev says in his article “Language Oriented Programming: The Next Programming Paradigm”:
Today’s mainstream approach to programming has some crucial built-in assumptions which hold us back like chains around our necks, though most programmers don’t realize this. With all the progress made so far in programming, we are still in the Stone Age. We’ve got our trusty stone axe (object-oriented programming), which serves us well, but tends to chip and crack when used against the hardest problems. To advance beyond stone, we must tame fire. Only then can we forge new tools and spark a new age of invention and an explosion of new technologies. I’m talking about limitations of programming which force the programmer to think like the computer rather than having the computer think more like the programmer.
- In the book “Science and Ultimate Reality” about John Archibald Wheeler, it’s stated that:
Some even go so far as to claim that the universe is a gigantic computer. The sociology underlying this line of thinking is interesting. There is a popular conception that science drives technology rather than the other way about, but a study of history suggests a more subtle interplay. There has always been a temptation to use the pinnacle of contemporary technology as a metaphor for nature. In ancient Greece, the ruler and compass, and musical instruments, were the latest technological marvels. The Greeks built an entire world view based on geometry and harmony, from the music of the spheres to the mystical properties associated with certain geometrical shapes. Centuries later, in Renaissance Europe, the clock represented the finest in craftsmanship, and Newton constructed his theory of the clockwork universe by analogy. Then in the nineteenth century the steam engine impressed everybody, and lo and behold, physicists began talking about the universe as a thermodynamic system sliding toward a final heat death. In recent times the digital computer has served as a seductive metaphor for nature. Rather than thinking of the universe as matter in motion, one could regard it as information being processed.
Physicists even computed how much information is possible to exist in any volume of space in the universe. See these two lectures for more details: “Rebooting The Cosmos: Is the Universe The Ultimate Computer?” and “A Thin Sheet of Reality: The Universe as a Hologram“. ↩
- E.J.Lowe, “Subjects of Experience”. Cambridge University Press 2006 ↩
- One of the jobs of a child learning language is to figure out which things are called by the same word. After learning that the family’s St. Bernard is a dog, the child may see a cow and say dog, thinking that the two things count as the same. Or the child may not realize that the neighbor’s chihuahua also counts as a dog. The child has to learn what range of objects is covered by the word “dog”. ↩
- Lera Boroditsky, “How Language Shapes Thought“. Scientific American, February 2011 ↩
- D. Wampler, T. Clark, “Guest Editors’ Introduction: Multiparadigm Programming”. IEEE Software, Issue 5 September/October 2010 ↩
- Here is one typical example in computational chemistry ↩
- Markus Voelter, “DSL Engineering: Designing, Implementing and Using Domain-Specific Languages”. CreateSpace Independent Publishing Platform 2013, available online ↩