Computing for Geometry: When the Going Gets Tough …

Complex Geometric Lamp Designs Produced with 3D Printing (Source)
In the previous post we read how our languages and ideas about the computational universe are best expressed using either a general purpose language with balanced human-computational aspects like Python or using a domain-specific language carefully crafted for our particular domain of abstractions. In this post, we will focus our attention on a specific domain for computation, geometric computing, and the design of geometry-specific programming languages.
Geometric Computing: The 6th Discipline
The ACM Computing Curricula 20051 defined “computing” as follows:
In a general way, we can define computing to mean any goal-oriented activity requiring, benefiting from, or creating computers. Thus, computing includes designing and building hardware and software systems for a wide range of purposes; processing, structuring, and managing various kinds of information; doing scientific studies using computers; making computer systems behave intelligently; creating and using communications and entertainment media; finding and gathering information relevant to any particular purpose, and so on. The list is virtually endless, and the possibilities are vast.
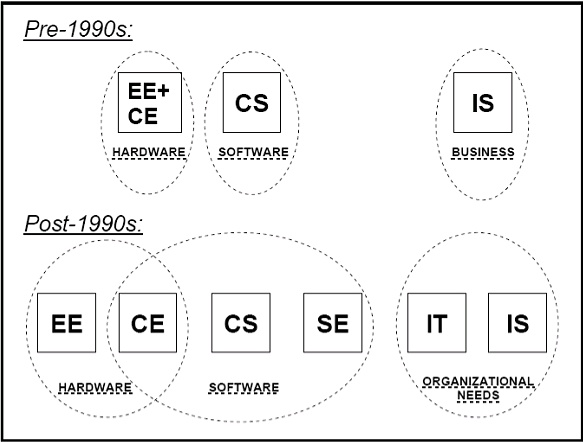
The report recognized five prominent sub-disciplines of the computing field: Computer Science (CS), Computer Engineering (CE), Information Systems (IS), Information Technology (IT), and Software Engineering (SE). I strongly believe Geometric Computing (GC) deserves to be added to these five. If we search the internet for the term “Geometric Computing” we probably will not find any specific definition. Many even identify “Geometric Computing” with “Computational Geometry”, which I think is a wrong idea as I will explain shortly. Borrowing from a 1989 ACM report on “Computing as a Discipline”2 we can adopt the following definition for geometric computing:
The discipline of geometric computing is the systematic study of algorithmic processes that describe and transform geometric information: their theory, analysis, design, efficiency, implementation, and application. The fundamental question underlying all geometric computing is “What (and how) geometric processes can be efficiently automated?”
From a teaching viewpoint, complete undergraduate and postgraduate academic programs should be designed for geometric computing; as is now common for the other five major computing disciplines. Such programs should include:
- Courses on specialized data structures for efficient geometric information storage, retrieval, and querying, like the ones in Prof. Hanan Samet‘s book “Foundations of Multidimensional and Metric Data Structures “, in addition to the traditional data structures of linked lists, stacks, queues, trees, graphs, and the like.
- A course on Euclidean and non-Euclidean geometries.
- A course on differential geometry for geometric modeling.
- A course on number theory and its applications in geometric information representation and processing.
- A course on numerical representation methods for geometric processing including floating-point numbers, exact numerical representations, and interval arithmetic as we discussed in a previous post.
- A course on geometric algebra for geometric modeling that we will investigate in following posts.
- A course on the properties and generation of geometric fractals.
- Courses on computational geometry including the use of libraries like CGAL and LEDA.
- Courses on computer graphics including ray tracing and global illumination techniques along with the traditional rendering techniques.
- Courses on GPU design and programming for general geometric processing not just for computer graphics.
- Courses on data visualization in 2D and 3D.
- Courses on DSL design and implementation for geometric computing applications.
- Courses on user interface design for geometric computing and geometric modeling software.
- Elective courses on applied geometric computing in-game engine design, simulation, geographical information systems, robotics, CAD\CAM, computer vision, and other related fields.
The mathematical courses in this list, like Euclidean and non-Euclidean geometries, differential geometry, geometric algebra, and number theory, should be taught as introductions with emphasis on applications, not mathematical rigor; similar to how we are teaching Fourier and Laplace transforms in electrical engineering courses for example. Many career opportunities are waiting for graduates of such geometric computing programs; just have a look here to get a general idea. Most traditional computing teaching programs do not provide specific training for these important and fast-growing career paths. A well designed geometric computing teaching program will create more advancement opportunities for both students and markets. I hope that someday I will have the opportunity to be one of the designers of a geometric computing academic teaching program.
Computational Geometry Out of the Way
In the light of the previous discussion, it was strange for me as a software engineer to find that most researchers in computational geometry consider it equivalent to geometric computing. In the 1970s the field of computational geometry emerged, dealing with geometric problems requiring carefully designed geometric algorithms for their solution. It can be defined as the systematic study of algorithms and data structures for geometric objects, with a focus on exact algorithms that are asymptotically fast. Many researchers were attracted by the challenges posed by the geometric problems. The road from problem formulation to efficient and elegant solutions has often been long, with many difficult and sub-optimal intermediate results. Today there is a rich collection of geometric algorithms that are efficient, and relatively easy to understand and implement. the algorithmic problems solved by computational geometry can be found in various application areas including robotics, computer graphics, CAD/CAM, integrated circuit design, computer vision, mesh generation for computer-aided engineering, and geographic information systems3.

Geometric computing is not just about finding algorithms with good complexity, this is just the “theoretical” aspect of geometric computing; one outstanding example of this fact in computer graphics is ray tracing. Because each ray is evaluated independently from the rest, ray tracing is “embarrassingly parallel,” with more processors being thrown at the problem usually giving a nearly linear performance increase. Ray tracing also has another interesting feature, that the time for finding the closest (or for shadows, any) intersection4 for a ray is typically order O(log n) for n objects, when an efficiency structure is used, like bounding volume hierarchies for example. This compares well with the typical O(n) performance of the basic Z-buffer, in which all polygons have to be sent down the graphics pipeline. Techniques such as hierarchical culling, level of detail, and impostors can be used to speed up the Z-buffer to give it a more O(log n) response. With ray tracing, this performance comes with its efficiency scheme, with minimal user intervention. Strangely enough, the main practical problem with ray tracing compared to raster graphics rendering is simply speed. The problem ray tracing faces is that, while O(log n) is better in theory than O(n), in practice each of these values is multiplied by a different constant, representing how much time each takes. For example, if ray tracing a single object is 1000 times slower than rendering it with a naive Z-buffer, 1000 log n = n, so at n = 9119 objects ray tracing’s time complexity advantage would allow it to start to outperform a simplistic Z-buffer renderer. One advantage of the Z-buffer is its use of coherence, sharing results to generate a set of fragments from a single triangle. As scene complexity rises, this factor loses importance. For this reason ray tracing is a viable alternative for extremely large model visualization5. The selection of which computational rendering technique to use is largely dependent on the details of the application not just the theoretical time-complexity of the computational algorithm.
The two most notable software libraries for computational geometry are The Computational Geometry Algorithms Library (CGAL) and The Library of Efficient Data types and Algorithms (LEDA); they reveal another distinction between computational geometry and geometric computing. Geometric computing is a form of geometry-specific software development. In geometric computing we can never be satisfied by a single library to say it’s equally suitable for all applications requiring geometric data representation and processing. Each geometric computing application has its unique characteristics and domain of ideas that deserves special care and requires unique software architecture. A computational geometry library like CGAL or LEDA can be a part of such architecture but it’s not the only part or even the only important part; the usability of the geometric computing application is certainly determined by many other factors. In this context computational geometry can benefit geometric computing as a general utility for rapid prototyping; computational geometry can, at the same time, benefit from geometric computing developments as well. Many practical concerns for creating computational geometry software are actually more related to general software engineering than to algorithmic complexity as we will see shortly; computational geometry libraries can be re-organized to deliver better performance for their computational aspect while being more accessible for their human aspect. Creating better geometric computing methodologies, practices, and DSLs can make libraries for computational geometry, robotics, computer graphics, and other geometric computing applications more accessible and practical to use.
Geometric State vs Geometric Action
In the English language, there are two kinds of verbs: State verbs and Action verbs.
- State verbs express states or conditions which are relatively static. They include verbs of perception, cognition, the senses, emotion, and state of being, like appear, believe, consist, contain etc. State verbs are not normally used in continuous forms. For example, we don’t say: “I am needing a new phone” but we can say: “I need a new phone”.
- Action verbs (also called dynamic verbs) express activities, processes, momentary actions or physical conditions like knock, leave, melt, read, etc. They may be used in continuous forms, for example: “Someone’s knocking at the door”.
A very similar situation can be found in our internal language of geometric reasoning, even if we’re not conscious enough about it most of the time. In all our geometric models we always have state geometric constructs and action geometric constructs:
- State geometric constructs contain key geometric information we need to store and change during the normal operation of the model. Two important examples found in computer graphics, robotics, and computer vision include position vectors (that represent points\locations in space) and frames (that represent poses\orientations of rigid bodies in space).
- Action geometric constructs contain processing information to move the model components between geometric states. For example, a direction vector can be used to move from one point to the other, and a rotation\translation matrix can be used to move from one orientation frame to another.
The mathematical tools used for representing these two very different types of geometric constructs are, unfortunately, more often than not, mixed without proper investigation of consequences. For example, we use the same 3-tuples of numbers to represent both positions (states) and directions (actions) in 3D Euclidean geometric models. Another example is the use of unit quaternions and rotation matrices to represent both orientations (states) and rotations (actions). The main problem here is the different geometric semantics of states and actions that should be reflected in their proper mathematical representations. For example, a direction vector is translation invariant while a position vector is not, we can interpolate rotations naturally but the same operation for orientations is not well defined. This situation is very common in practical geometric computing software implementations, typically leading to many special cases and parametric singularities that need to be specifically handled. Such mixing of state\action representations increases the difficulty for debugging and creating modular geometric computing code 6.
Geometry > Algebra > Algorithm > Code

Geometry is essentially a visual and imaginative human activity, it’s mathematically modeled using the language of algebra, computational algorithms are derived from the algebra and geometry, and finally, software is coded from the algorithms. Each step of these four is a world of challenge and creativity on its own7:
- First of all, we need to be geometrically imaginative, to think and reason in geometry; this requires talent and training like any other form of human art8!
- Next, we need to select suitable algebraic representations for our geometric objects and algebraic operations for the geometric processing we which to apply. Some representations are purely algebraic, like implicit and parametric equations for curves and surfaces. More often geometric representations are combinatorial in nature, an object is represented as a collection of simpler objects and a set of constraints on them. Take a look at the following question: given a circle of radius r, what is the locus of this circle if its center moves on a curve? We know that the locus, usually referred to as a sweep, looks like a tube; but, it is not so easy to know what exactly this tube looks like. If the curve is a line normal to the plane of the circle, the locus is a right cylinder. The difficult part is that the curve is not a line and/or that the radius of the given circle can change. Therefore, we have an easily described geometric operation whose algebraic counterpart is somewhat complicated.
- Some algorithms are straightforward to derive from the algebraic representations; for example, finding the intersection point (or verifying there exists one) of two lines in 2D given their implicit equations. The general case is far from simple, however, and a combination of symbolic, numeric, approximate, and geometric processes are applied to find a fully functional computational algorithm.
- The final step, that many erroneously choose to ignore initially as being straightforward, is coding the algorithm into working software. Translating geometric algorithms to programs requires extreme care in each step: from the correct selection of a number system to represent and store geometric data with acceptable accuracy, to the handling of special cases of the algorithm, and designing a suitable user interface that actually works for the specific application. In addition, the exact same algorithm may be generally coded using a universal matrix algebra library, or specifically coded for a few special cases depending on the requirements of the application.
Moving from Abstract to Concrete
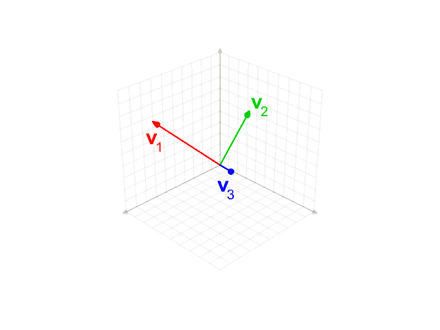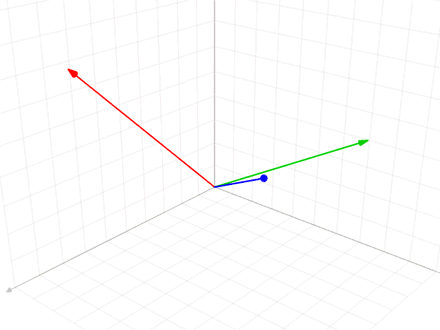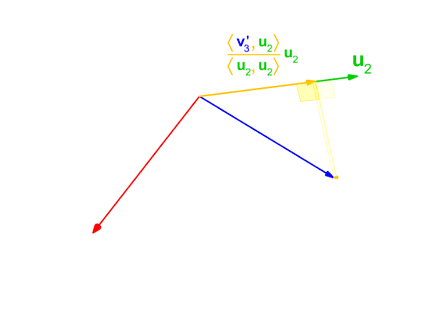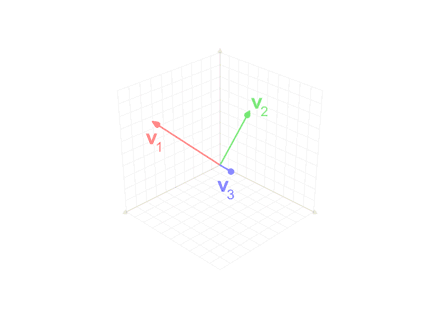
When we move from the most abstract level of geometric thinking to the most concrete level of software coding we face many questions. Taking the Gram–Schmidt process for converting a set of linearly independent vectors into a set of orthonormal vectors of the same finite size as a very simple example. First, we define the projection operator of one vector v on another vector u by:
![]()
Then the procedure goes as follows:
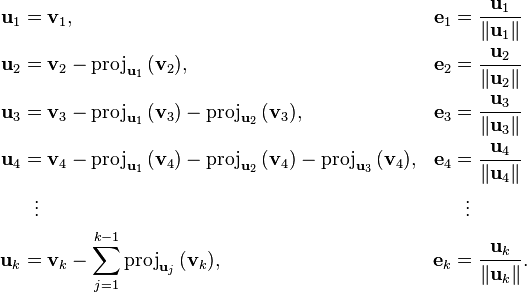
We need to carefully study some points to implement this algebraic algorithm successfully:
Input\Output Representation. The basic geometric components of this problem are n linearly independent vectors (the inputs) and n orthonormal vectors (the outputs). How are we given the inputs and how should we deliver the outputs? Many options exist including using tuples, using single row or column matrices, or using a class\structure with x,y, and z components (if our vectors are in 3D). In addition, which computational number system should we use for the vector components? Exact rational numbers, floating-point numbers, etc. Another important consideration is whether to use classes or structures (i.e. using the heap or the stack) for concrete vectors; both methods are algorithmically equivalent but are very different implementation-wise.
Sub-Process Representation. The basic algebraic operations on the vectors throughout the process are vector projection on another vector, vector normalization, the inner product of two vectors, vector subtraction, and vector scaling by a number. A typical OOP way of thinking would define each operation in a separate subroutine and call the inner product subroutine from the projection subroutine, the projection subroutine from the main loop subroutine, and so on; this is not the most efficient implementation, however, we will see why in the following points to come.
Intermediate Results Representation. During our computational processes, many intermediate results are required. Depending on the nature of the computation some results persist until the end and some are just needed for a few steps. Typical OOP would use the same representation for all geometric objects (in this case vectors) of the problem whether being input, output, or intermediate objects especially inside the isolated subroutines for the basic sub-processes. This would probably lead to many stack\heap allocations damaging the net performance of the implementation. This is one crucial difference between geometric procedure and software subroutine. The design of the intermediate results representation should be considered carefully under many possible domain-specific optimizations.
Geometric Primitives Selection. Most geometric representations are combinatorial in nature. But what primitives should be combined to generate the conceptual geometric objects? We find many typical examples including point clouds, triangular meshes, NURBS, subdivision surfaces, circles, spheres, cubes, and much more. No single selection of primitives is suitable for all geometric computing applications. For example, 3D CSG modeling software typically uses solids like cones, spheres, boxes, and similar primitives. Then the software internally transforms these into triangular meshes or point clouds for data storage and exchange with other software systems. Other applications like 3D laser scanning and LIDAR remote sensing initially generate huge volumes of point clouds that need grouping and processing to be humanly accessible. How can we select and manipulate the best set of primitives for our geometric computing application is an important aspect.
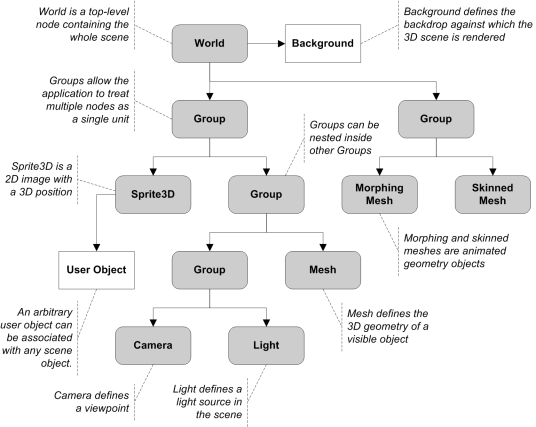
Combinatorial Depth. When trying to represent a simple geometric concept like a line we have many choices. We can use two point objects, one point and one unit vector objects, a set of numbers for the line’s Plücker coordinates, a simple set of 6 numbers (x1, y1, z1, x2, y2, z2) for the two points of the line, and much more. Now we can represent a plane as a combinatorial tree of one line and one point, or as a simple list of 9 numbers (the coordinates of the plan’s three points). Each representation selection is a combination of other geometric objects. We then can choose to create “deep” or “shallow” combinatorial trees for complex objects. How deep should we allow our representations to go will affect performance, code readability and maintenance, and data storage and exchange capabilities. Deep representations are good for human understanding while shallow implementations are better for low-level computing provided that we can write, or generate, the code for manipulating them.

Mixing Representations. Even the simplest of abstract geometric objects have many representations. Mixing a parametric and implicit representation for circles, for example, inside the same software can be useful for implementing different algorithms that work well for different representations. For example, point generation algorithms are trivial for parametric representations while incidence queries are easier for implicit representations. How should we code such multiple representations? One choice is to create a base class, for example, “Circle”, and inherit several representations from it (CircleP and CircleI) implementing specific algorithms on the child classes and automatically selecting, and converting to, the most suitable representation for a given algorithm. Another choice is to use a standard canonical representation for all objects (like BREP for geometric surfaces) and apply automatic conversions at each computational step of our algorithms. A third choice is by creating separate representation classes and let the user explicitly enforce what representation to use for a given algorithm and control conversion process manually. Each choice of the three has its benefits and problems.
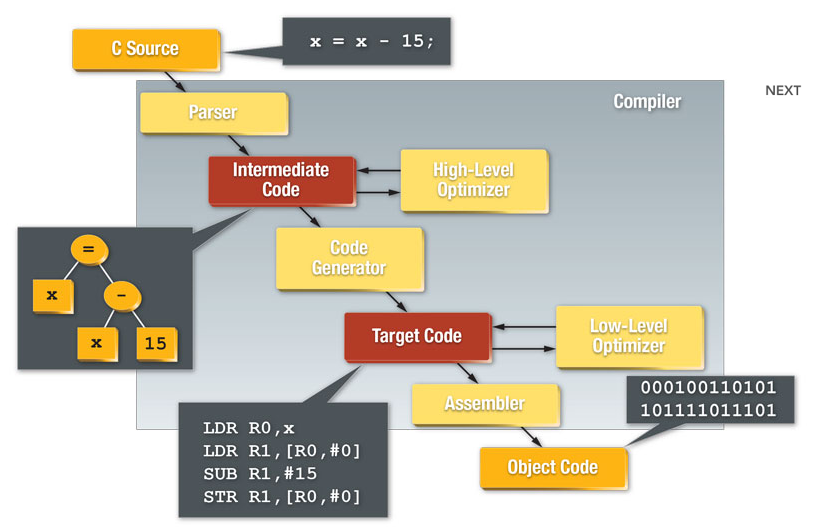
Domain-Level Optimizations. A typical modern optimizing compiler for a general-purpose programming language can generate and optimize the final machine code very well if the code exhibits locality (for example belongs to the same subroutine). Compilers can eliminate many local low-level computational redundancies but have no clue at possible high-level, more abstract optimizations especially when the computational algorithm implementation is scattered across several classes and subroutines. In my experience high-level domain-specific optimizations are more critical to performance than low-level code optimizations. To approach these we need a solid understanding of the details of our geometric algorithm and even then we often miss a lot of possible optimizations. In addition, performing manual domain-level optimization is too difficult and error-prone to be carried to its full extent. It’s sometimes possible to optimize the algorithm as a whole by uniformly representing its objects and processes using the “shallowest” possible combinatorial tree representations; now we are dealing with a set of arithmetic number computations that can be expressed as an easy to optimize, very low-level, and large directed graph. This approach is partially possible using code generation and geometric algebra as I will explain in later posts and illustrate throughout this website.

Rapid Prototyping. If we have a geometric idea that we need to explore and we have to wait for several days until a suitable code is written so that we can see how it goes we would probably go find better things to do instead. Rapid prototyping is very important for practical geometric thinking and realization of ideas. The success of interactive geometry software like Cinderella, The Geometer’s Sketchpad, and GeoGebra in teaching and exploring geometry is one pointer to the importance of rapid prototyping in geometric computing. One other remarkable success story is Grasshopper on Rhino, a very interesting visual DSL for the procedural creation of complex 3D geometric constructions using intuitive geometric computing visual blocks that has vast practical use in art, design, and architecture9 10.
Process Testing and Debugging. In modern software, we need test cases to find bugs in our system. The problem with geometric algorithms is the many special cases that might not be obvious from the start. In this particular example, one special case is when some of the input vectors are (completely or nearly) linearly dependent when one or more are near zero, or when large variations in vector lengths are present in the input vectors; we need to study these special cases carefully to design our test code. In addition, stepping through the code while being executed is of little benefit; we need strong visual clues for each step of the computation; after all we a, e dealing with geometric computing that is visual by nature in most aspects. We also need algebraic assertions with significant geometric meaning; for example, after finishing the orthogonalization procedure we may get the dot-product of each pair of output vectors and assert it’s very near to zero. Designing suitable tests is fundamental to geometric computing just like to any software system development.
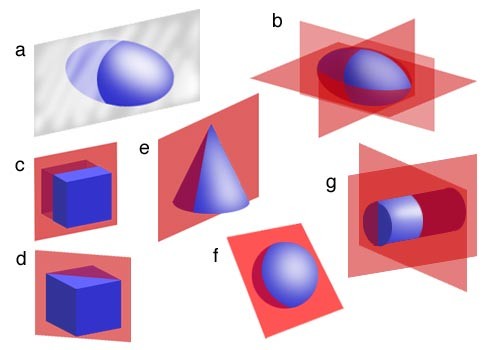
Geometric Representation\Process Invariance and Computation Time. Geometry is symmetric by nature, the selection of the coordinate system is arbitrary, at least in theory, to enable using n-tuple computational representations for vectors on a given basis. This is called coordinate-free geometry, or more accurately coordinate-invariant. Practically, this ideal is almost impossible to achieve but we, the geometry implementers, tend to live with the problem. For example, computing with floating-point numbers makes it impossible to preserve the invariance of the Gram–Schmidt process for any arbitrary basis, but guarantees near constant computation time for the same number of input vectors. If we use exact arithmetic, the computation time for, say, 3 vectors depends on the relative relation between the vectors in space and the selected basis (axis); now process invariance is computationally preserved, but computation time is varying widely because of the use of exact numeric computations. This problem is central to implementing many geometric computing systems even if the computational geometry algorithm is well-studied to be algorithmically efficient. A form of stability analysis for the computational algorithm in terms of accuracy and time requirements is needed. In the terminology of Modeling and Simulation, this process is generally called system accreditation.
Numerical Error Control. Many geometric processes are very sensitive to numerical errors. If you try to find the intersection point of two lines in 3D represented by the coordinates of two points each, a total of 12 numbers, any small error in any of the 12 numbers will result in two non-intersecting lines. Exact equality testing is not a good idea in such cases but interval inclusion is usually used instead. Some case studies exist for showing the severity of this problem for geometric algorithms implementations like the ones here and here.

Query vs. Compute Consistency. Due to a bad selection of basic numeric representations or bad algorithm design many query algorithms return different results from their corresponding computation algorithms. For example, one may create query code to test if two given lines intersect in 3D that answers true for some input, while the computation code for finding the actual intersection point fails. This is a very serious problem that requires special care for implementing consistent query-computation code especially for special cases in geometric computing.
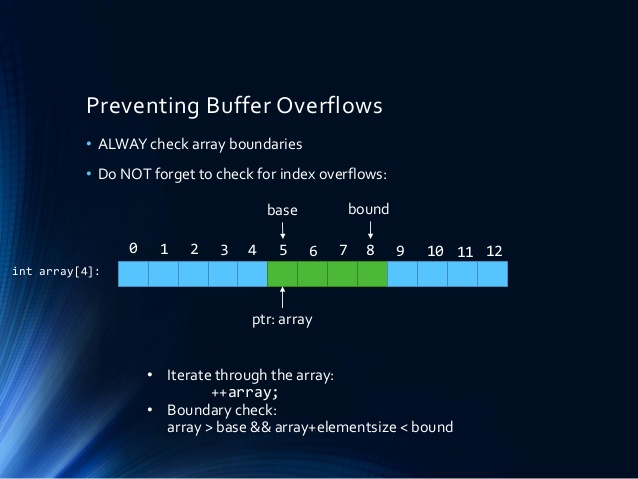
Using Arrays, Loops, and Indirect Memory Access. Many direct implementations of geometric algorithms rely on looping, arrays, and other indirect memory access schemes; this should be avoided as much as possible. For example, if we need to compute Gram–Schmidt process for only 3D vectors we should create a structure with 3 members not a single array of 3 elements. The reason for that is the access of local variables takes fewer instructions than accessing array items that may require indirect memory access (i.e. pointer arithmetic) and array bounds checks. The difference may seem insignificant at first but anyone who created a game engine or a real-time flight simulator knows it’s not; every processor cycle counts. Writing the manual code will get more difficult but performance will be better than using a for loop on an array, as the case for inner product computation for example. The problem of manual coding in such case can be easily solved using automatic code generation techniques.
A Geometric Computing Conclusion
In this post, I tried to give a definition to Geometric Computing as a very important but currently very scattered discipline of computing deserving the development of specialized teaching programs. I tried to differentiate and relate geometric computing and computational geometry. I also tried to describe the steps involved in creating a concrete software implementation from our abstract geometric ideas. Finally, I have a list of some significant problems we need to answer when designing geometric computing software. In the next posts, I will try to describe how good use of Geometric Algebra and some standard software engineering methods can address many of the problems listed in this post. Until next time, I hope you follow and enjoy.
- The Joint Task Force for Computing Curricula 2005, “Computing Curricula 2005: The Overview Report”. Online ↩
- D. E. Comer et al, “Computing As a Discipline”. Community ACM Vol. 32. Num. 1, January 1989 ↩
- Mark de Berg, Otfried Cheong, Marc van Kreveld, “Computational Geometry, Algorithms and Applications, Third Edition”. Springer 2008 ↩
- Intersection computations is the main geometric operation in ray tracing that requires most of the processing time ↩
- Tomas Akenine-Moller, Eric Haines, Naty Hoffman, “Real-Time Rendering, Third Edition 3rd Edition”. CRC Press 2008 ↩
- For more information about this important topic, you can read any book on Affine Geometry in computer graphics like “An Integrated Introduction to Computer Graphics and Geometric Modeling” by Ronald Goldman, and this good paper on the problems of representing rotations and orientations in geometric computing here ↩
- Take a look at the theme of the online course notes on “Computing with Geometry” by Dr. Ching-Kuang Shene ↩
- To get an idea of how geometric thinking works, see the book edited by Sue Johnston-Wilder and John Mason, “Developing Thinking in Geometry”. SAGE Publications Ltd 2005 ↩
- See this video for an illustration and see here for more Grasshopper featured galleries ↩
- One other very interesting use of Rhino was accomplished using functional programming with F# for designing the Cladding of the Louvre Abu Dhabi Dome; see here for some details ↩